Overview of Amazon Aurora Database
Amazon Aurora is a fully managed Relational Database Service (RDS), designed grounds-up to be a cloud-native database meant to meet performance needs of cloud-native applications.
Key Points
- Administration
- Fully managed by Amazon, automating administration tasks like provisioning, patching, backups, recovery, failure detection and repairs.
- No need to provision storage – starting from 10 GB (which is minimum), as your need grows, Aurora can automatically scale up to 64 TB with no impact on database performance
- You can scale the compute resources (for your Aurora DB instance) by selecting the right DB Instance class
- You can change Instance class for an existing DB Instance and apply changes either immediately, or let it apply during your specified maintenance window (either way, there will be availability impact for few minutes)
- Aurora is MySQL and PostgreSQL compatible
- Aurora delivers up to five times the performance of standard MySQL databases and up to three times the performance of PostgreSQL databases.
- MySQL and PostgreSQL compatibility
- Most of the code, applications, drivers and tools used for MySQL / PostgreSQL databases can be used with Aurora with little or no change.
- A small set of features however may not be available on Aurora – such as MySQL’s MyISAM storage engine
- Migration options – from MySQL / PostgreSQL to Aurora, or vice-versa
- Use standard mysqldump / pg_dump to export data from MySQL / PostgreSQL, and mysqlimport / pg_restore to import data to Aurora.
- Use Amazon RDS’ DB Snapshot migration feature to migrate RDS MySQL DB (/ PostgreSQL) Snapshot to Aurora using AWS Management Console
- Backup and Restore
- Automatic Backups
- Aurora backs up your cluster automatically and retains restore data for the length of the backup retention period.
- Backup retention period can be from 1 to 35 days. Unlike RDS, you cannot disable automatic backups in Aurora.
- Backups are continuous and incremental, and stored in S3.
- Backups do not affect performance of the database services
- You can restore to any point within the backup retention period.
- Manual Backups
- You can manually take a Snapshot of the data. This is retained until you manually delete it.
- Restore
- You can recover your data simply be creating a new Aurora DB cluster from the backup (Automatic backup / Snapshot).
- You can restore a DB cluster to a specific point in time.
- Backtrack (MySQL compatible edition only)
- This feature allows your quickly move to a prior point in time without needing to restore from a backup (such as in case of user errors – wrong table drop / wrong deletion)
- Can go up to 24 hours in the past – it makes use of change logs
- Automatic Backups
Architecture of Amazon Aurora
Aurora has a very difference architecture compared to its other RDS counterparts (on AWS). Aurora is designed in a cluster architecture – which provides the resiliency and performance that Aurora is known for.
The Aurora DB Cluster architecture looks like this:
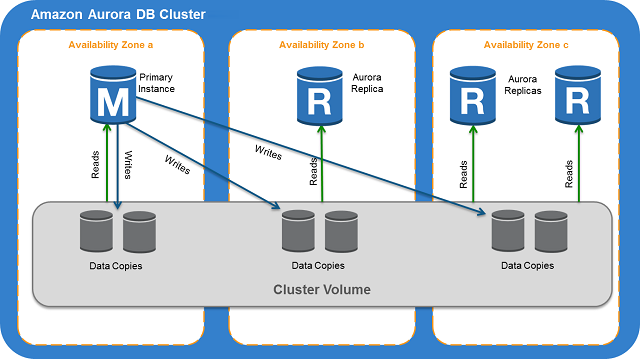
Image courtesy of AWS
To understand Aurora Cluster, you need to look at two different aspects:
- Storage architecture – Cluster Volume
- DB Instances architecture
Storage architecture:
Aurora makes use of Cluster Volume to store the data. This Cluster Volume is a virtual volume that uses solid state drives (SSDs) and stores (six) copies of data across multiple AZs (within the same Region). Aurora engine architecture takes care of data replication across the AZs, and multi-copies provide you with high durability of your data as well as high availability (across AZs).
Notes:
- Cluster volumes automatically grow with the increase in the amount of your data
- You are only charged for the space that you use in a Cluster Volume
Warning: Though you are only charged for the space you use in a Cluster Volume, you need to be aware of a tricky part of this equation. AWS considers your usage based on a concept called “high water mark”. That is – your usage is marked based on the maximum amount that was allocated for the Aurora Cluster at any point in time. Most of the time this is not an issue, because applications tend to grow in associated data-footprints. But, if for any reason your data dramatically reduces in size, you would be paying for more volume size than you are “truly” using. In order to remedy this situation, you must perform a logical data dump and restore to a new cluster, using a tool such as mysqldump. Snapshots do not help in this case because Snapshots retain the physical layout of the underlying storage.
For this matter avoid running operations (e.g., ETL) that lead to temporary higher usage.
DB Instance architecture:
This component of Aurora Cluster consists of one or more DB instances. There are two types of Aurora DB instances
- Primary DB instance – this is the main instance and can perform both read and write operations on the underlying (storage) cluster volume.
- Each Aurora DB Cluster has only one Primary DB instance.
- Aurora Replica – this instance connects to the same underlying (storage) cluster volume as the Primary DB instance does, but it can only perform read operations.
- Each Aurora DB Cluster can have up to 15 Replicas. Best practice is to spread these Replicas across AZs
Notes:
- Aurora automatically fails over to a Replica when the Primary DB instance becomes unavailable. You can specify the priority for Replicas.
- Additionally Replica(s) can offload read operations from the Primary DB instance
- Since data is handled independently of the instances, when you add a new DB Instance (to same Aurora DB Cluster) it is up and running quickly because data is already there for its operations – that is no data replication is needed when you add a new instance within the same Aurora DB Cluster.
Architecture Variations
Multi-master cluster:
Aurora does allow setup of Multi-master cluster, which enables all DB instances to have capability of read and write operations.
- In Multi-master cluster, your application controls which requests are handled by which DB instance, by way of connecting to individual endpoint.
- When it comes to storage architecture Multi-master cluster is similar to standard architecture (Master <> Replicas) – data is stored across AZs in multiple copies, and grow automatically.
- Currently there is a limit of two DB instances in case of Multi-master cluster.
Aurora Global Database
Aurora Global Database allows database to span multiple AWS Regions.
- This architecture consists of one Primary Region, and up to five Secondary Regions.
- Secondary Regions are read-only.
- Writes are performed directly to Primary Region, via DB cluster endpoint of the Primary cluster.
- Enables great local (read) performance by virtue of low latency in each Region
- Enables Disaster Recovery in case of complete Region outage
- It replicates your data across Regions, with no impact on database performance.
- There are several restrictions when it comes to Aurora Global Database architecture, such as (this is only a small list):
- Only available for select versions of MySQL and PostgreSQL
- Only select-few compute instance classes available (e.g., db.t2/3 not available)
- In case of upgrades, you must first upgrade the secondary cluster.
- Features like Cloning, Backtrack, Parallel query, etc., are not available
Pricing
Following are the key components of Aurora pricing:
- Database Instances – charged per hour for a running instance – based on selection of compatible database type (MySQL / PostgreSQL) and compute instance type (e.g., db.t3.small, db.t3.medium, db.r5.large, etc.)
- Database Storage – charged per GB per month of storage used
- IOs – Charged per 1 million I/O requests
- Backup Storage – charged per GB per month of Storage used for backup
- There is no additional charged for backup storage if its size is up to 100% of your total Aurora database storage – this also covers the scenario when you have backup retention period set to 1 day (because backup storage would never pass 100% of your database storage, provided you are not doing any additional backups)
- Data Transfer – charged per GB per month of data transferred out of RDS
- Backtrack – charged per 1 million Change Records per hour
- Snapshot Export (to Parquet format) – charged per GB of Snapshot size
Though mentioned above in the storage architecture section, it’s worth repeating here in the Pricing section:
Warning: Though you are only charged for the space you use in a Cluster Volume, you need to be aware of a tricky part of this equation. AWS considers your usage based on a concept called “high water mark”. That is – your usage is marked based on the maximum amount that was allocated for the Aurora Cluster at any point in time. Most of the time this is not an issue, because applications tend to grow in associated data-footprints. But, if for any reason your data dramatically reduces in size, you would be paying for more volume size than you are “truly” using. In order to remedy this situation, you must perform a logical data dump and restore to a new cluster, using a tool such as mysqldump. Snapshots do not help in this case because Snapshots retain the physical layout of the underlying storage.
For this matter avoid running operations (e.g., ETL) that lead to temporary higher usage.
External Resources


