Overview of Amazon DynamoDB
Amazon DynamoDB is a Key-Value and Document database, part of NoSQL database category.
Key Points for Amazon DynamoDB
Features
- DynamoDB is fully managed high performance database
- DynamoDB is multi-Region, and multi-Master database
- Performance – DynamoDB can handle more than 10 trillion requests per day and can support peaks of more than 20 million requests per second.
- DynamoDB Accelerator (DAX) is an in-memory cache that delivers high performance for read operations.
- DynamoDB does support ACID transactions that are typically hallmark characteristics of Relational Databases.
- To support ACID, DynamoDB does consume higher Capacity Units.
- Besides Primary Key, you can also query based on non-primary key attributes, by using Secondary Indexes (Global Secondary Index, Local Secondary Index).
Administration
- DynamoDB is a fully managed service
- There are no servers to provision, patch or manage
- DynamoDB automatically scales up and down to adjust for application’s needs
- DynamoDB takes care of partitioning and re-partitioning as the data footprint grows
- You have option between on-demand capacity and provisioned capacity
Architecture – Key components of DynamoDB
- Tables – a Table is a collection of data.
- Example – Employee table that may contain employee basic info such as Employee ID, Name, Department, etc.
- DynamoDB Tables are schema-less. That is, the items within a Table don’t need to conform to same set of attributes. All the items, however, do need to have the attribute that makes up the Primary Key for that Table.
- Items – an Item is like a record, a group of attributes that define a particular entry in the Table.
- In above example of Employee Table, “Jane Doe” along with other data (like “E9001” as ID, “HR Department” as department, etc.), would make one item. Each Item is unique within a Table.
- Attributes – Attributes are the basic elements that make up an Item.
- For example, in above example of Employee Table, Employee ID, Name, Department, etc., are the attributes.
- Attributes can be nested. That is – each attribute can have a structure that contains multiple attributes. DynamoDB supports up to 32 levels of nesting.
How DynamoDB works
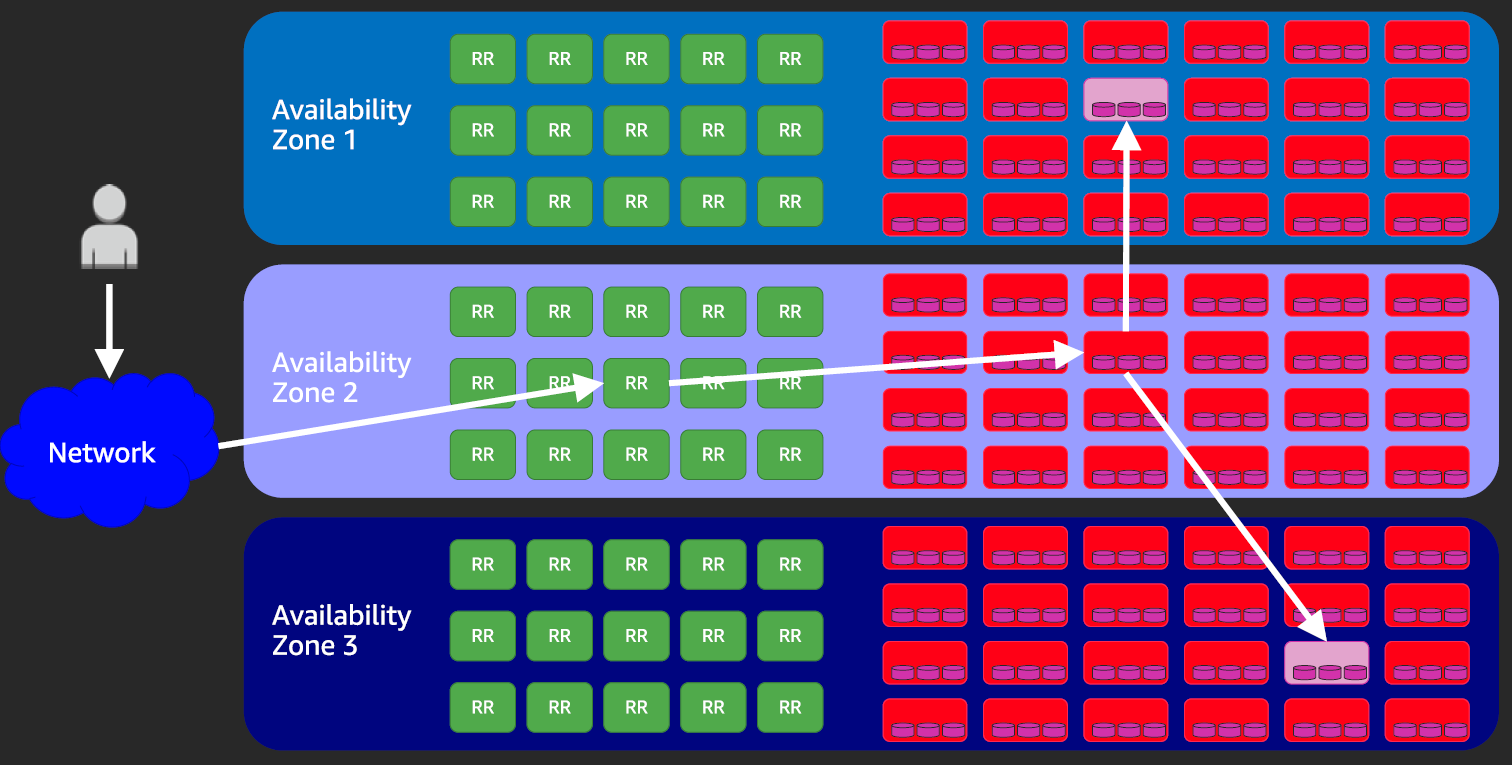
DynamoDB stores data by partitions, and stores each partition on three storage nodes (spread across three AZs for higher availability and data durability). One of those three nodes is the lead node for that partition, and always have up to date data.
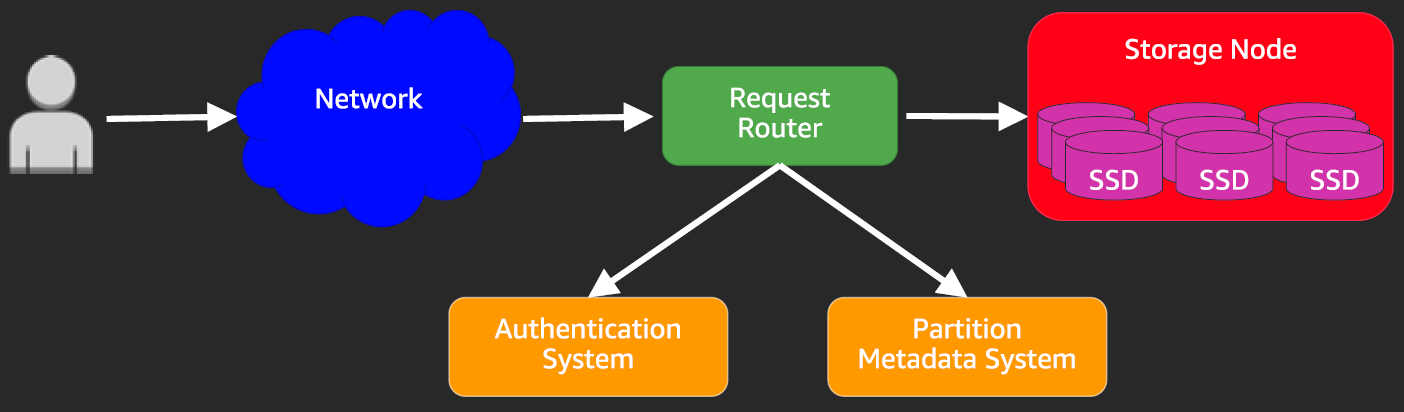
There are multiple components that make the functioning of DynamoDB feasible, but two components are worth discussing here:
- Request Router
- Storage Node (cluster)
Courtesy – AWS re:Invent talk by Jaso Sorenson
Request Router:
This component is a server that acts as a broker to route DynamoDB operation requests to the right Storage Node. To perform the process it also accesses:
- Authentication System – to authenticate and authorize the requesting principal
- Partition Metadata System – to fetch information regarding storage node (and their mapping to partitions).
Storage Node:
This is where the data is stored.
- When a write operation is performed, Request Router waits until the write is successful on at least two (of the three storage nodes).
- Data is then asynchronously copied to the third one. This is what could cause stale data in case of eventually consistent reads
As you can imagine, DynamoDB architecture actually has thousands of Request Routers and thousands of Storage Nodes to provide with high availability and fault tolerance.
Courtesy – AWS re:Invent talk by Jaso Sorenson
Composition of Table Keys
Primary Key
In a Table a Primary Key uniquely identifies each item of that Table. DynamoDB supports two kinds of Primary Keys
- Partition Key
- A Primary Key composed of single Attribute is known as a Partition Key
- DynamoDB calculates a Hash on the Partition Key and uses that Hash value to determine the partition to store that item on. A Partition is the actual (physical) storage where DynamoDB data is stored on.
- Partition Key is also called Hash Key / Attribute
- In our above example of Employee Table, Employee ID is the single attribute that defines this table’s Primary Key, and thus is also the Partition Key
- Composite Primary Key
- This type of Primary Key consists of two attributes – a Partition Key and a Sort Key.
- For each item in a Table the combination of these Keys must be unique. That is – two items may have same Partition Key, but then they must have different Sort Key.
- DynamoDB uses the Partition Key to calculate Hash and store in a given (storage) Partition, and within that Partition all other items with the same Partition Key are sorted based on the Sort Key
- Partition Key is also called Hash Key / Attribute
- Sort Key is also called Range Key / Attribute
- In our above example, if we could have Department as the Partition Key, and the Employee ID as the Sort Key.
- Unlike other Attributes of a Table, the attribute(s) that make the Primary Keys, are not allowed to be nested. The only types allowed for them are string, number, or binary.
Secondary Indexes
For efficient querying – outside of querying on Primary Key – DynamoDB allows defining Secondary Indexes. A Secondary Index, in essence, allows you to query the Table using an alternate key (that is – alternate to the Primary Key).
- Secondary Indexes have the structure of the Composite Primary Key -that is – they have a Partition Key and a Sort Key.
- There is a cap of 20 Global Secondary Indexes and 5 Local Secondary Indexes per Table
DynamoDB allows defining Secondary Indexes in to ways:
- Local Secondary Index
- This is an Index which uses the original Partition Key of the Table, along with a new Sort Key.
- Global Secondary Index
- In this case the Index can have both Partition Key and Sort Key different from the original Partition / Sort Keys of the Table
Data Consistency – because DynamoDB is performing replications behind the scene, it does so (by default) in asynchronous mode. Thus there may be a stale data in some copies, at times. It does give you options to chose the one that fits your application needs:
- Eventually Consistent Reads
- An eventually consistent read may yield stale data at time – when a recent write has not been propagated to all data-copies yet.
- All copies usually reach the consistent state within a second.
- This mode does maximize read throughput.
- Strongly Consistent Reads
- A strongly consistent read always returns a result that reflects all the successful writes that have happened before this read.
ACID transactions – DynamoDB does support ACID (Atomicity, Consistency, Isolation, and Durability) for your applications, with the constraint that it is restricted to a single (AWS) Account and is within the same Region.
Additional Features of DynamoDB
DynamoDB Accelerator (DAX)
If you want enhanced (read) performance of DynamoDB data, you can enable DynamoDB Accelerator (also called DAX). With DAX, your read performance would go from single-digit milliseconds (standard) to microseconds.
DAX is implemented as an in-memory cache. To provide a high-scale performance, it is created as a cluster of cache nodes (see diagram below):
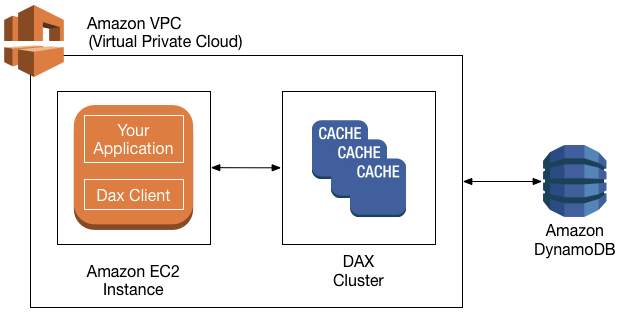
Image courtesy of AWS
Key notes:
- DAX is meant for read performance, and it helps performance with following operations:
- GetItem, BatchGetItem, Query, Scan
- DAX does a pass-through to DynamoDB in case of Strongly Consistent Reads.
- For write operations, DAX does a pass-through to DynamoDB Table(s). For following operations, data is first written to DynamoDB table(s), and then to DAX cluster (to cache updated data):
- PutItem, BatchWriteItem, UpdateItem, DeleteItem
- DAX does not handle operations meant for Table design, such as CreateTable, UpdateTable. These must be performed directly on the DynamoDB.
DynamoDB Streams
DynamoDB Streams allow you to capture data changes happening on your DynamoDB Tables.
- Events (of data changes) appear in a stream, in near real-time and in the order in which the change events are occurring.
- Events are triggered when an item is added, updated, or deleted in the Table.
- Each such event is a considered a Stream Record and makes available following data
- Item image (in different forms, depending on add/ update / delete):
- Item is added – Stream Record provides the entire item
- Item is updated – Stream Record provides both the “before” and the “after” image of the attributes that were changed
- Item is deleted – Stream Record provides the entire item that was deleted
- Name of the Table
- Event Timestamp
- Metadata
- Item image (in different forms, depending on add/ update / delete):
- DynamoDB Streams may be used for
- Triggering various functions or workflows, when combined with Lambda
- Data replication within and across Regions
Backup and Restore for DynamoDB
There are two primary ways of backups on DynamoDB tables:
- On-demand backup
- Automatic Continuous Backup with point-in-time recovery
On-demand Backup, and Restore
Backup:
With on-demand backup, you can perform full backup of DynamoDB data at any time.
- This backup is retained until manually deleted.
- Backup is done asynchronously and it does not affect regular operational performance.
- Backup operation does not consume provisioned throughput.
- You can schedule periodical backups via one of the following ways:
- AWS Lambda functions – trigger them on a schedule
- AWS Backup service – a centralized place for backups (caters to more than just DynamoDB)
Restore:
You can do a full table restore from the backup, or can restore along with additionally change some of the table settings.
- Table settings you can change while performing a restore
- Global Secondary Index(es), Local Secondary Index(es), Billing mode, Provisioned Read and Write Capacity, Encryption settings
- You can restore DynamoDB table across AWS Regions
- Following settings must be manually set on the restored table:
- Auto Scaling policies
- IAM policies
- CloudWatch metrics and alarms
- Tags
- Stream settings
- Time to Live (TTL) settings
Continuous Backup, and Point-in-Time Recovery (also called PITR)
Backup:
With continuous backup (once enabled) you don’t need to worry about taking manual backups. DynamoDB is continuously taking backups, and with the help of its own set of markers and change logs it can restore your data to the time and date of your choice (going back up to 35 days in the past).
- Backups are retained up to 35 days – it’s a rolling backup mechanism, in which snapshots that are older than 35 days are discarded.
- You can enable PITR on each local Replica of a global table.
- CloudTrail logs all console and API actions for PITR to enable logging, continuous monitoring, and auditing.
- If you delete a table that has PITR enabled, a system backup is automatically created and kept for 35 days.
Restore:
You can restore a table to any point of time going back up to 35 days in the past.
- If PITR was enabled in the past 35 days, you can only go up to that time. Also, if you disable and re-enable PITR on a table, you can only go back up to the time of re-enabling of PITR (or 35 days, if re-enable was more than 35 days ago).
- You can do a full table restore, or restore table with changes to following settings:
- Global Secondary Index(es), Local Secondary Index(es), Billing mode, Provisioned Read and Write Capacity, Encryption settings
- You can restore DynamoDB table across AWS Regions
- Following settings must be manually set on the restored table:
- Auto Scaling policies
- IAM policies
- CloudWatch metrics and alarms
- Tags
- Stream settings
- Time to Live (TTL) settings
Read / Write Capacity Mode
Read / Write Capacity modes two key aspects: one, how you want capacity be managed, and two, how you are charged for your read and write throughput.
There are two modes how DynamoDB can process reads and writes on your data.
- On-demand
- Provisioned
On-demand Mode
This mode provides you with the flexibility of not having to worry about capacity planning. This is ideal for cases like – your workloads are irregular or unpredictable, or you are just starting out and don’t know what the load or patterns might be.
When you use On-demand mode for your DynamoDB database, you do not specify capacity units, and are charged based on consumption. This consumption is measured in terms of Read Request Units and Write Request Units (for read and write operations respectively).
- Read Request Unit
- One Read Request Unit is needed for one strongly consistent read request, or for two eventually consistent read requests, of an item up to 4 KB in size.
- Two Read Request Units are needed to perform one transactional (ACID) read of items up to 4 KB.
- If the Item is larger than 4 KB, DynamoDB uses additional Read Request Units. Example – to perform a strongly consistent read of a 15 KB item, DynamoDB would consume 4 Read Request Units.
- Write Request Unit:
- One Write Request Unit is needed to write an item of up to 1 KB in size.
- Two Write Request Units are needed to perform one transactional (ACID) write of item up to 1 KB.
- If the Item is larger than 1 KB, DynamoDB uses additional Write Request Units.
- Under On-demand mode, DynamoDB automatically scales (up / down) per your application’s needs
- Previous Peak Traffic: at any given time this mode can accommodate up to double double the previous peak traffic. DynamoDB continues to gear-up per your need, your application may experience throttling if its traffic more than doubles (compared to its previous peak traffic) within 30 minute window.
- Example: if your application (let’s say, using strongly consistent reads) is running between 10,000 and 20,000 reads, the Previous Peak Traffic is considered 20,000 reads. DynamoDB can easily accommodate when the load grows up to 40,000 reads at which point it would set the Previous Peak Traffic to 40,000. Then DynamoDB can accommodate up to 80,000 reads. However, if within 30 minutes of the time when 80,000 peak was established, your application traffic goes past 160,000, then it may start to experience throttling. Once that 30 minute window has passed, DynamoDB should not have any problem doubling it again.
- From your perspective, this could also prevent a scenario where not only your load, but your bill shoots up unexpectedly very high.
- DynamoDB starts new tables with a Previous Peak of 2,000 Write Request Units and 6,000 Read Request Units.
- If you are converting a table from Provisioned Mode to On-demand mode, then Previous Peak is established at half the maximum WCUs / RCUs previously provisioned on those tables. If either of the number is lower than default of New Table Peaks, then default of New Table Peaks are used.
Provisioned Mode
When you have fair or general idea of your workload, you go with Provisioned Mode. When you select this mode, you specify the number of reads and writes per second that you would like (to provision) for your application.
The way you specify your reads and writes is through number of RCUs and WCUs.
- Read Capacity Unit (RCU):
- One RCU represents one strongly consistent read per second, or represents two eventually consistent reads per second, of an item up to 4 KB in size.
- Two RCUs are needed to perform one transactional (ACID) read per second, of item up to 4 KB.
- If the Item is larger than 4 KB, DynamoDB uses additional RCUs.
- Write Capacity Unit (WCU):
- One WCU represents one write per second, of an item up to 1 KB in size.
- Two WCUs are needed to perform one transactional (ACID) write per second, of item up to 1 KB.
- If the Item is larger than 1 KB, DynamoDB uses additional WCUs.
- Provisioned throughput is the maximum amount of capacity than an application can consume from a table or index. If your application exceeds this capacity, your application may experience throttling.
- when a request is throttled, your application would request HTTP 400 code (Bad Request).
- You do have an option to additionally leverage Auto Scaling to adjust your provisioned capacity automatically in response to your workload.
- Reserved Capacity – you can purchase reserved capacity in advance to achieve cost savings. When you do this, you are committing to a minimum provisioned usage (just like it’s in case of EC2 Reserved Instances).
Key Operations in DynamoDB
DynamoDB supports following key operations on Tables:
- CreateTable – create a table
- DescribeTable – show details of a table
- ListTables – show names of the tables (for the current AWS account and Region)
- UpdateTable – modify one of the following configuration
- Table’s provisioned throughput settings (applicable only for provisioned mode tables)
- Table’s read / write capacity
- Table’s Global Secondary Index(es)
- Enable or disable DynamoDB Streams on the Table
- DeleteTable – delete a table
- DescribeLimits – show current read and write capacity quotas (for the current AWS account and Region)
DynamoDB supports following key operations on Items:
- PutItem – create an item
- GetItem – read an item
- UpdateItem – update an item
- DeleteItem – delete an item
- BatchGetItem – read up to 100 items from one or more tables
- BatchWriteItem – create or delete up to 25 items in one or more tables
DynamoDB supports following operations for fetching data from the tables:
Query – reads items based on Primary Key and other specified parameters
- Parameters include such as:
- Key Condition Expression – match set of criteria
- Partition Key must have “=” criteria
- Sort Key can optionally have additional comparison criteria (such as =, <, <=, >=, Between)
- Filter Expressions – to additionally filter out the results returned based on Key Condition Expression
- Limit – limit the number of items to be fetched
- Read Consistency – you can set ConsistentRead operation to true to perform strongly consistent reads. Default is false and does the eventually consistent reads.
- Key Condition Expression – match set of criteria
- You can get additional info along with the results
- Number of Items in results
- ScannedCount – total number of items that matched the Query (before Filter Expressions were applied)
- Count – total number of items that matched the filtered results of the Query (that is – it’s the count of results after Filter Expressions were applied)
- To get Capacity Units consumed by the Query, you can set the ReturnConsumedCapacity parameter in the Query to one of the following:
- NONE – does not return consumed capacity data (default value)
- TOTAL – returns total number of RCUs consumed
- INDEXES – returns total number of RCUs consumed, together with the consumed capacity for each table and index that was accessed
- Pagination – results are paginated with each page of data of size 1 MB (or less)
- Number of Items in results
Scan – reads every item in a table or a secondary index.
- Parameters to filter results
- ProjectionExpression – used to return only some attributes (instead of all attributes, which is the default)
- Filter Expressions – applied on the results to discard a set of items (from the full scan results)
- Limit – limit the number of items to be fetched
- Read Consistency – you can set ConsistentRead operation to true to perform strongly consistent reads. Default is false and does the eventually consistent reads.
- Parallel Scan – you can set the values of Segment and Total Segments to run Scan in parallel using multiple nodes
- Do watch out for Parallel Scan as it can quickly consume your provisioned throughput
- You can get additional info along with the results
- Number of Items in results
- ScannedCount – total number of items that matched the Query (before Filter Expressions were applied)
- Count – total number of items that matched the filtered results of the Query (that is – it’s the count of results after Filter Expressions were applied)
- To get Capacity Units consumed by the Query, you can set the ReturnConsumedCapacity parameter in the Query to one of the following:
- NONE – does not return consumed capacity data (default value)
- TOTAL – returns total number of RCUs consumed
- INDEXES – returns total number of RCUs consumed, together with the consumed capacity for each table and index that was accessed
- Pagination – results are paginated with each page of data of size 1 MB (or less)
- Number of Items in results
Security
- DynamoDB encrypts all data at rest, by default, using encryption keys stored in KMS
- You have the choice of following Customer Master Keys (CMK), to encrypt table(s):
- AWS owned CMK – default, and no additional charge
- AWS managed CMK – additional charges apply
- Customer managed CMK – additional charges apply
- DynamoDB also encrypts the data in transit
Pricing
Pricing is dependent on the type of capacity mode selected for the Table.
On-demand capacity mode:
- Read and Write
- Read – per million Read Request Units
- Write – per million Write Request Units
- Storage – per GB per month, above 25 GB (first 25 GB is free)
- Backup and Restore
- Continuous Backups (PITR) – per GB per month
- On-demand Backup – per GB per month
- Restore – per GB restored
- Global Tables – per million replicated Write Request Units
- DAX – charged per node-hour, and is dependent on underlying instance type (e.g., t2.small, r4.xlarge, etc.)
- DynamoDB Streams – per 100,000 Read Request Units performed on DynamoDB Streams (first 2,500,000 are free every month)
- Data Transfer – per GB data transferred out (first 1 GB is free every month)
Resources
- DynamoDB’s official page: https://aws.amazon.com/dynamodb/
- DynamoDB Pricing: https://aws.amazon.com/dynamodb/pricing/


