What are the key characteristics of Data, and Databases?
In this article, we will talk about key characteristics of Data Storage and Databases, from difference aspects, and also talk about the key fundamentals that various Databases pick and choose to addresses a specific set of challenges (faces by various applications).
Storage Persistence
Let’s start with Data storage characteristics in terms of persistence. At a high level data storage (devices or software) address persistence in one of the three following ways:
Persistent
- Typically long-term storage
- Durable – lives past the instance / engine stop
Transient
- Temporary storage- more like a pipeline for data in / out
- Some persistence mechanisms (through high availability or data flush) may exist to avoid complete loss of data during crashes or intentional shut-down of instances
Ephemeral
- Just a playground for compute machines to perform processing on the data
- Short-lived, and does not persist after instance is stopped or restarted
Storage Performance Characteristics
Storage performance always come at a cost. So, you carefully pick the level of performance desired (for your application needs). There are two main characteristics that you evaluate:
IOPS (Input / Output Operations per Second)
- In simple terms, this is how fast the storage device / system can move the data
Throughput
- This is how much of data the storage device / system can move at a time
Data Governance Principles characteristics – adopted by Database Systems
This is a set of characteristics that Database Systems adopt and thus architect their implementation against. There are two main camps of how what set of characteristics are important for applications.
ACID
- Atomicity – all changes (pertaining to a single transaction) take place, or none of them does
- Consistency – data in the database must be in valid state before and after the transaction completes.
- Valid data means that the data is compliant with all the rules (like constraints, triggers, referential integrity, etc.) defined with the database
- Isolation – each transaction is isolated from other concurrently happening transactions. That is – concurrent transactions do not make their changes visible to each other. Such changes are visible for any transaction only after a transaction has successfully completed.
- Durability – once the transaction has successfully completed, its changes persist even if the database engine / instance crashes
BASE
- Basically Available – basic data reading and writing is available most of the time, but it may lack guarantee of consistency
- Reads may not get recent writes (stale data issue)
- Writes may be lost post reconciliation of conflicts
- Soft Sate – different nodes (specially replicas) may not be mutually consistent at a given time
- Eventually Consistent – with passage of time the data will be consistent
- in most systems, this passage of time is in milliseconds.
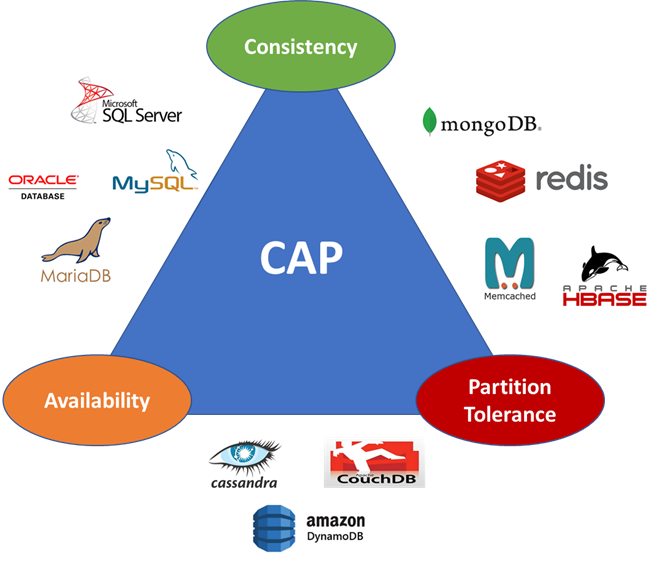
CAP Theorem
There is an interesting theorem – CAP theorem (also called Brewer’s theorem named after Eric Brewer) – that spells three key characteristics of database systems, and boldly states that any database system can only pick two of the three characteristics in a proper way.
It’s a simple concept that stacks ACID and BASE against Consistency, Availability and Partition Tolerance
- Consistency – at least one copy of the database will have consistent (up to date) data
- note: this Consistency is different from Consistency from ACID concept in the way, ACID’s consistency is for data in a valid state against data rules and constraints
- Availability – every request will get response without any error, though the data might be stale
- Focuses on availability versus the up to date data
- Most databases implement mechanism to have a leader node that would allow updates on up to date data, but may allow read of (potentially) stale data from slave nodes
- Partition Tolerance – the system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between the nodes
Following diagram shows select-few databases are how they stack on choosing the primary two of the three characteristics of the CAP theorem: