AWS Lake Formation is an awesome data and analytics related (fully managed) service that enables you to create a secure Data Lake fast – in days.
But, what is a Data Lake?
In simple terms, a Data Lake is a repository where you can store all type of (related) data, including data that is structured, semi-structured, and structured. You can include raw data as well as transformed data in that Data Lake.
An easy way to visualize it is to compare it with a natural lake that intakes many different streams of water – from different sources. Some of that water may be clean, some dirty, some with various types of minerals, or even dump from polluted sources.
The purpose of Data Lake is to create a central place where all of your (related) data exist. That way, your applications (typically analytics applications) would not have to integrate with multiple sources. The Data Lake, if done right, can increase the speed of analytics, and result in better insights.
Even though it sounds like that a Data Lake is simply a data-dump (which it is), and would be easy to setup, in practice it takes lot of effort, resources and time to create the data-flows from various sources to this Data Lake. Tasks such as integration, load / unload of data, security (access, encryption, etc.), data cleansing, at times data-format handling, cataloging, etc., can cause lot of headaches and can turn out to be costly (in terms of $$ and time). This is where AWS Lake Formation service can help. AWS Lake Formation can expedite the process of setting up Data Lake for your applications and analytics.
Conceptual view of how AWS Lake Formation works:
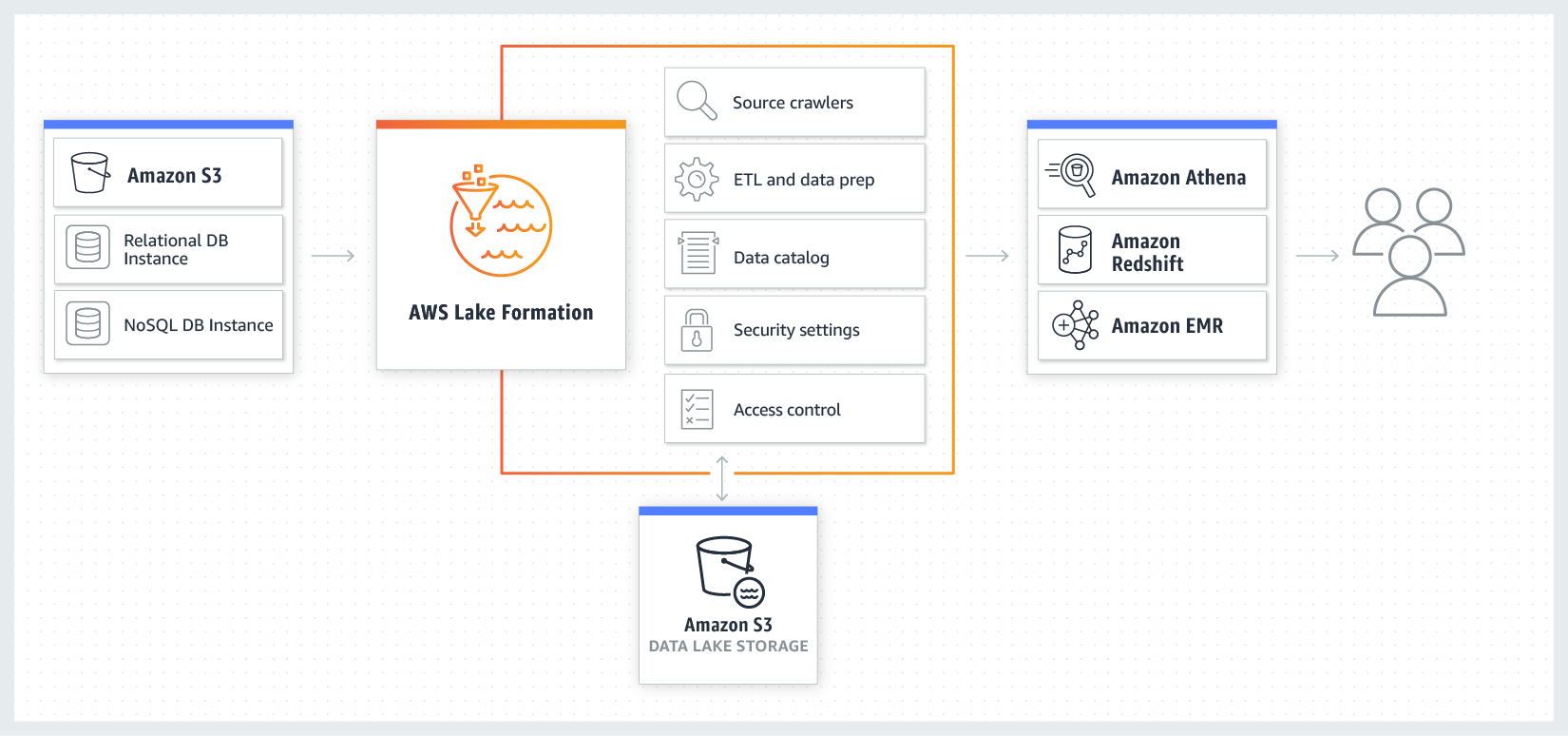
Image courtesy of AWS
Key features and benefits that AWS Lake Formation brings to you
- Easily and quickly setup Data Lakes
- Import data with ease – whether from AWS data sources or from on-prem sources
- Use Blue Prints to load data – that handle complexity under the hood for you
- Automating much of Data Catalogs help enable self-service for your project / organization
- Lake Formation automatically discovers all AWS data sources to which it is provided access to
- Lake Formation makes use of AWS Glue workflows, and uses similar Catalogs
- Automation of data-cleansing and deduplication
- Lake Formation deploys advanced mechanisms to analyze large volume of data for redundant data in a fairly short period of time
- Simplification of security management like Access Controls, Encryption, and Logging
- Uses S3 as the base
- Lake Formation keeps the data in standard format, stored on S3. You are not locked into AWS since no proprietary formatting is used.
- Lake Formation provides APIs and CLI, thus enabling integration with your custom applications.
You can seamlessly integrate following services with Lake Formation, including applying permission management:
- Amazon Athena
- Amazon EMR
- AWS Glue
- Amazon Redshift Spectrum
- Amazon QuickSight
Pricing
There is no additional charge for Lake Formation. You pay for the underlying resources used, such as:
- AWS Glue
- Amazon S3
- Amazon EMR
- Amazon Athena
- Amazon Redshift
External Links


