Amazon Kinesis is a set of services that enable collection, processing, and analyzing of streaming data in real-time. It allows ingestion of real-time data such as video, audio, application logs, website clickstreams, and IoT telemetry data – which you can then process or analyze in real-time, and direct to appropriate to storage.
What is Streaming Data?
Streaming Data is a continuous flow of data that is being generated by sources (often multiple sources – sometimes thousands of them). Typically these streams consist of small chunks of data – often in Kilobytes.
Challenges with such data:
- Handling such data can be challenging due to massive volume, and perhaps multiple formats coming from various sources.
- In many scenarios the data becomes stale pretty quick – especially if you are trying to analyze and make near-real-time decisions.
Amazon Kinesis consist of four services:
- Kinesis Data Streams
- Kinesis Video Streams
- Kinesis Data Firehose
- Kinesis Data Analytics
Key characteristics of all Kinesis services
- Fully Managed
- Real-time ingestion and processing
- Highly Scalable
In this article, we will focus on Kinesis Data Streams
Amazon Kinesis Data Streams (Amazon KDS)
Amazon Kinesis Data Streams service allows you to ingest a large amount of streaming data in real-time, durably stores the data, and make the data available for consumption (processing and analysis).
Composition of data stream:
- KDS stores data in units – each unit called a data record
- Data stream consist of multiple data records
- Within the Data Stream, data records are grouped in Shards
- Data records within each Shard are sequenced (ordered)
Following diagram shows simplified view of how Kinesis Data Streams works:
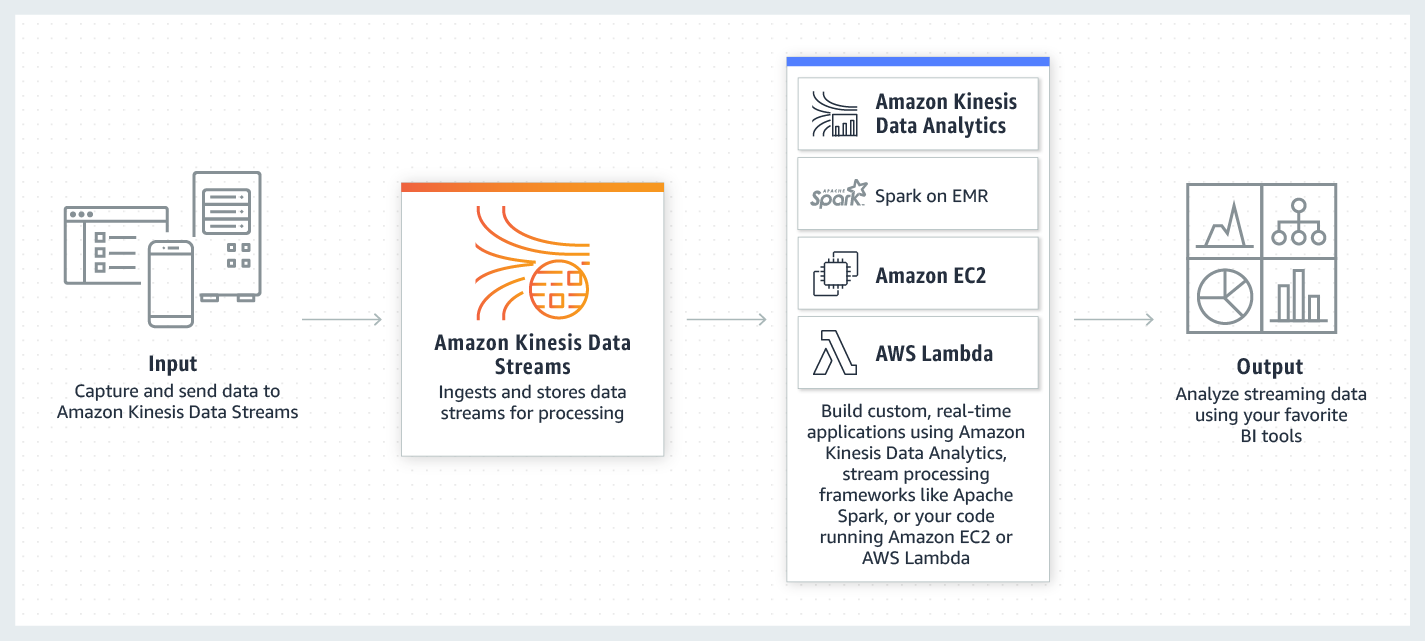
Image courtesy of AWS
Key Components of Kinesis Data Streams
(Kinesis) Data Stream
- Consists of a set of Shards
- Data is generated by Producers, and consumed by Consumers (applications that read data off Kinesis Data Streams)
(Kinesis) Data Record
- A data record is the unit of data stored in a Kinesis data stream.
- Data records are composed of a sequence number, a partition key, and a data blob, which is an immutable sequence of bytes.
- Kinesis Data Streams does not inspect, interpret, or change the data in the blob in any way.
- A data blob can be up to 1 MB.
(Kinesis) Shard
- A shard is a uniquely identified sequence of data records in a stream.
- A stream is composed of one or more shards, each of which provides a fixed unit of capacity.
- Each shard can support:
- Max of 5 transactions per second for reads
- Max of up to a maximum total data read rate of 2 MB per second and up to 1,000 records per second for writes, up to a maximum total data write rate of 1 MB per second (including partition keys).
- The data capacity of your stream is a function of the number of shards that you specify for the stream. The total capacity of the stream is the sum of the capacities of its shards.
- When you define a Stream, you specify number of shards the Stream can handle – this determines the capacity of your Data Stream (sum total of capacities of Shards within the Stream)
- You can calculate initial number of shards you may need based on following formula:
- number_of_shards = max (incoming_write_bandwidth_in_KB / 1024, outgoing_read_bandwidth_in_KB / 2048); where
- incoming_write_bandwidth_in_KB = average data size in KB x number of records per second
- outgoing_read_bandwidth_in_KB = incoming_write_bandwidth_in_KB x number of consumers
Partition Key – the key identifier that Kinesis Data Streams uses to know which Shard does a Data Record belong to
Sequence Number – within Shard, each Data Record is identified by its Sequence Number, which also puts Data Records in an order within the Shard
Following diagram shows Stream and Shards flow:
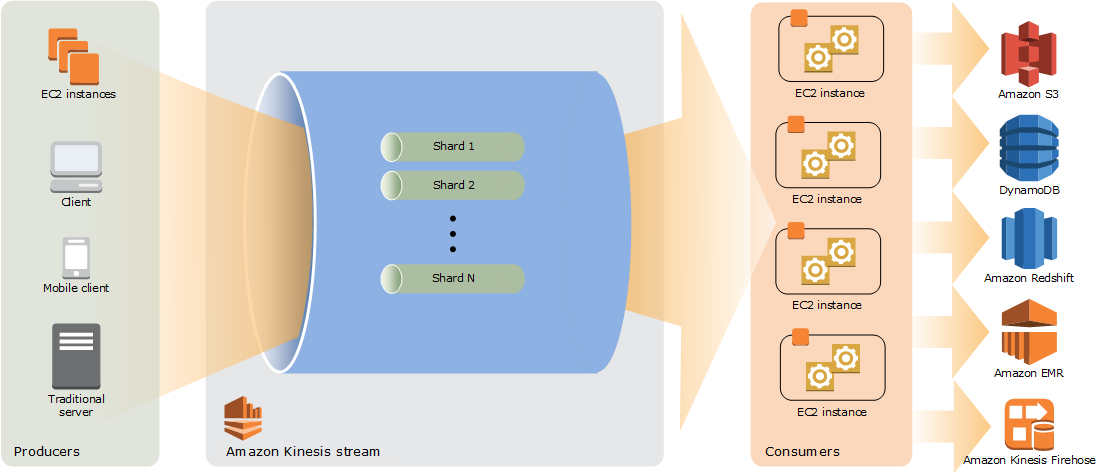
Image courtesy of AWS
Supporting components
Kinesis Client Library (KCL)
- KCL is a pre-built library that enable your Kinesis applications to read and process data from Kinesis data stream.
- Libraries are available for Java, Python, Ruby, Node.js, .NET
- This library is compiled into your application to enable fault-tolerant consumption of data from the stream.
- KCL ensures that for every shard there is a record processor running and processing that shard.
- KCL uses DynamoDB to stores control data.
- AWS recommends to use KCL over Kinesis API, as KCL performs heavy-lifting tasks associated with distributed stream processing, making application development easier and faster.
Enhanced fan-out
- Enhanced fan-out feature provides a logical 2 MB/sec throughput pipes between consumers and shards.
- It enables multiple consumers reading from a data stream in parallel, while still maintaining high performance.
- Consumers register themselves with Kinesis Data Streams to get their (logical) pipes created.
- Not all consumers need to be registered – you can selectively register the consumers that need such throughput.
SubscribeToShard API
- SubscribeToShard API is a high performance stream API that pushes data from shards to consumers over a persistent connection (over HTTP/2) without a request cycle from the client.
- The persistent connection can last up to 5 minutes
- Typically delivers the data arriving on the shard, to consumers within 70 milliseconds – which is ~65% faster than GetRecords API
- KCL v2.x supports SubscribeToShard API
- This feature is only available with enhanced fan-out composition
Additional Key Points
- Kinesis Data Streams keeps all incoming data for up to 24 hours from the time they arrive in shards. You can increase this window to up to 7 days for additional charge.
- Maximum size of data lob within one record is 1 MB.
- Each shard can support up to 1,000 PUT records per second.
- Each shard has ingest capacity of 1 MB per second, or 1,000 records per second
- Each shard provides up to 2 MB per second of data output for all consumers.
- This can be adjusted to 2 MB per second for each consumer when enhanced fan-out feature is enabled.
- Encryption – data can be encrypted using Server Side Encryption (recommended), or you can encrypt / decrypt data on the client side
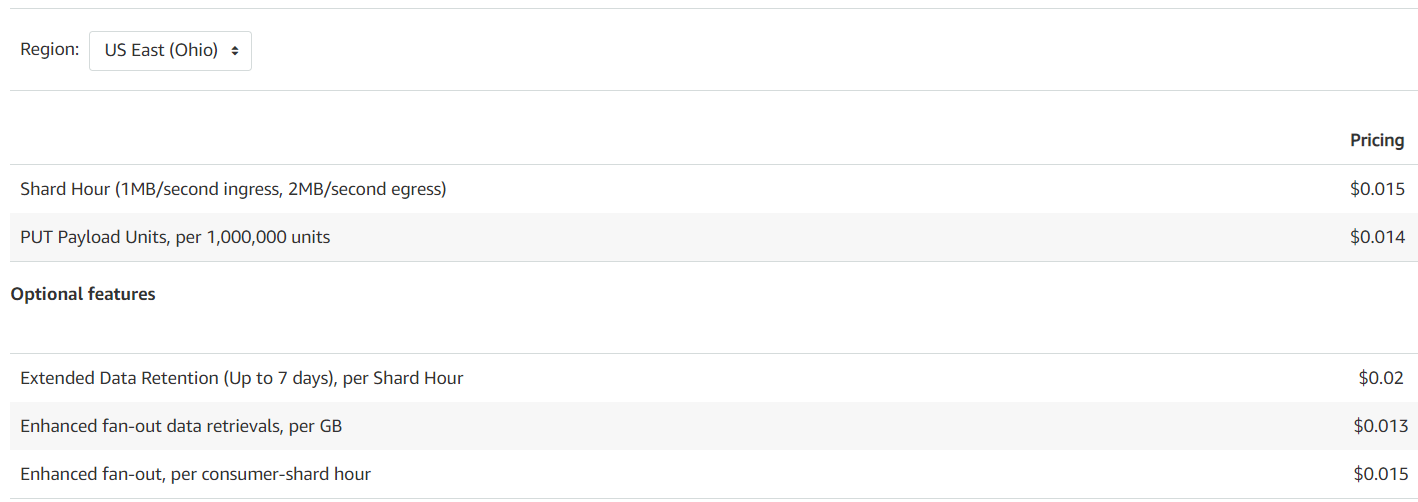
Pricing
Kinesis Data Streams is billed for following components:
- Shard Hour – per shard per hour
- PUT Payload Unit – per PUT Payload Unit (25 KB)
- Examples:
- A 2 KB record is 1 PUT Payload Unit
- A 35 KB record is 2 PUT Payload Units
- A (max capacity) 1 MB record is 40 Payload Units
- Examples:
- Enhanced fan-out charged on:
- per consumer shard hour, and
- Per GB of data retrieved
- Extended Data Retention – per each shard hour incurred
Here is an example rate from AWS (rates change with time):
External Resources


